



Everything you need to know about MCP - Model Context Protocol.
wtf is MCP?


What is MCP and the MCP Server?
The Model Context Protocol (MCP) is an open standard that defines a universal way to connect AI models (especially large language models) with external data sources and tools . In simple terms, MCP provides a common protocol so that AI applications (like chatbots, coding assistants, etc.) can retrieve data or perform actions by interfacing with external systems in a standardized manner – think of it as a “USB-C port for AI applications” that allows plug-and-play integration of various data sources .
An MCP server is a lightweight program or service that implements this protocol, exposing certain capabilities (data access or tool-like functions) to AI systems. It acts as a bridge between an AI assistant and external services/APIs . For example, an MCP server could connect to a database, file system, or web API and present those resources or actions in a uniform way to any AI client that speaks MCP. Developers can either build AI applications that act as MCP clients or create MCP servers that expose data/tools; the MCP standard ensures they can communicate seamlessly . In summary, MCP defines how an AI assistant can ask a server for information or to perform an operation, and the MCP server is the component that understands those requests and executes them on the appropriate external data or service.
Why was MCP Created? (The Problem it Solves)
Modern AI assistants often need access to private knowledge bases, documents, or services to give relevant answers. Before MCP, integrating an AI model with each data source or API was a bespoke effort – every new integration required a custom connector or plugin. This led to a fragmented “M×N” integration problem: if you have M AI applications and N different tools/data sources, you would end up building and maintaining M×N custom integrations . This approach is clearly unscalable, resulting in duplicated effort, inconsistent interfaces, and siloed information. In analogy, it was like the pre-USB era of hardware, where each device needed its own special cable/driver .
MCP was created to standardize these integrations and reduce complexity. By providing one universal protocol, MCP turns the integration challenge into an “M+N” problem (each AI app implements an MCP client, and each tool or data source provides an MCP server) . All AI assistants can then speak the same language to any data source that supports MCP. This replaces fragmented, one-off APIs with a single, cohesive interface, making it much simpler and more reliable to give AI systems the data access they need . In short, MCP’s goal is to enable truly connected AI systems by breaking down data silos. Instead of being “trapped” away from the user’s data, an AI model can safely query an MCP server to fetch relevant context or invoke operations, without each integration being a special-case implementation.
Before MCP vs. After MCP: Without a standard like MCP, an LLM needed custom code to integrate with each service (Slack, Google Drive, GitHub, etc.), creating many point-to-point connections. With MCP, the LLM or host application talks to a single standardized interface, and any number of backend services can be plugged in behind that interface.
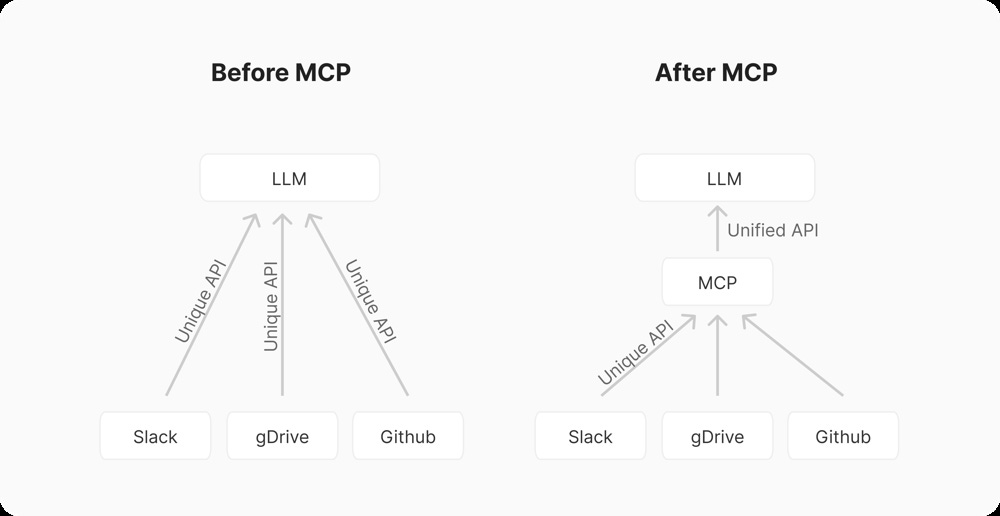
By introducing a common protocol, MCP also facilitates interoperability and vendor flexibility. An AI tool built to use MCP servers can switch out one MCP server for another (for example, swapping a local database for a cloud database) without changing how the AI interacts with it. This decoupling improves maintainability and scalability in complex AI workflows . It also allows sharing and reusing integrations: a growing list of pre-built MCP connectors can be reused across different AI applications, avoiding re-inventing the wheel for each new project .
Who is Developing and Advocating for MCP?
MCP was introduced and open-sourced by Anthropic in late 2024 . Anthropic leads the development of the specification and provides reference implementations, but MCP is an open standard with a community of contributors. The official MCP website and GitHub organization (modelcontextprotocol) host the specification, SDKs (Software Development Kits), and a collection of open-source MCP server examples . Multiple SDKs exist (TypeScript, Python, Java, Kotlin, C#, etc.) to help developers implement the protocol in their language of choice . This open ecosystem means that the protocol is not tied to a single vendor; anyone can implement an MCP server or client by following the spec.
Anthropic has integrated MCP support into its products (for example, Claude AI’s desktop app can use local MCP servers), and several other organizations have begun adopting or promoting MCP. Early adopters include companies like Block and Apollo, who have integrated MCP into their systems, and developer tool companies such as Zed (code editor), Replit, Codeium, and Sourcegraph, who are working with MCP to enhance their AI-assisted development platforms . For instance, Sourcegraph’s Cody code assistant uses MCP to fetch relevant context (like issues from project trackers or code from repositories) to improve its responses. The idea is quickly gaining traction as a vendor-neutral way to connect AI agents with the wealth of data and services that live outside the LLM’s own model parameters.
The MCP initiative is actively evolving via community input. There are blog posts, tutorials, and even contributions from independent developers experimenting with MCP servers for various APIs. This broad involvement suggests that MCP is being viewed as a common good – analogous to how standards like HTTP or USB are maintained – rather than a proprietary API. Even other AI players have taken notice: for example, OpenAI’s tools/agents documentation references MCP as a method for providing context to language models , and Microsoft’s Semantic Kernel team has discussed MCP in the context of connecting plugins to LLMs . This cross-industry interest further solidifies MCP’s role as a standard protocol layer for AI integration moving forward.
MCP Architecture and Components
MCP follows a client–server architecture with clear role separation :
MCP Host: The application where the user interacts with an AI model (e.g. a chat interface, IDE, or assistant app). The host incorporates an AI model and one or more MCP clients.
MCP Client: A component (often a library within the host application) that maintains a 1:1 connection to an MCP server. If the user’s AI assistant needs to talk to multiple external systems, the host will create multiple MCP client connections (one per server).
MCP Server: An external program or service that provides data and tools to the AI via the MCP protocol. Each server exposes a specific set of capabilities (for example, one server might interface with Google Drive, another with a Weather API).
These components communicate over a transport layer that can vary. Typically, if the server is running locally (on the same machine as the client), the communication uses standard input/output streams (stdin/stdout) – a lightweight mechanism also used by protocols like the Language Server Protocol . For remote or networked scenarios, MCP can operate over HTTP using Server-Sent Events (SSE) to maintain a streaming connection . In either case, the messaging format is JSON-RPC 2.0, which MCP uses as the “wire protocol” for encoding requests and responses . Every message is a JSON object indicating a method (like an action or query) and parameters, or a result. This choice of JSON-RPC means the protocol inherits a well-tested request/response structure with support for bidirectional notifications (allowing the server to send updates/events back to the client if needed) .
MCP servers expose three primary types of content to clients: Tools, Resources, and Prompts. Each type corresponds to a different mode of interaction and is treated slightly differently by the AI system. Figure 1 below illustrates these components at a high level, and how they map to who (model, application, or user) controls them:
Overview of MCP client/server capabilities: an MCP server can expose executable Tools, readable Resources, and reusable Prompts. The MCP client (inside the host app) invokes or queries these on behalf of the LLM. Tools are typically invoked by the AI model (with user approval), Resources are provided to the model under the app’s control, and Prompts are preset by developers or users to guide interactions .
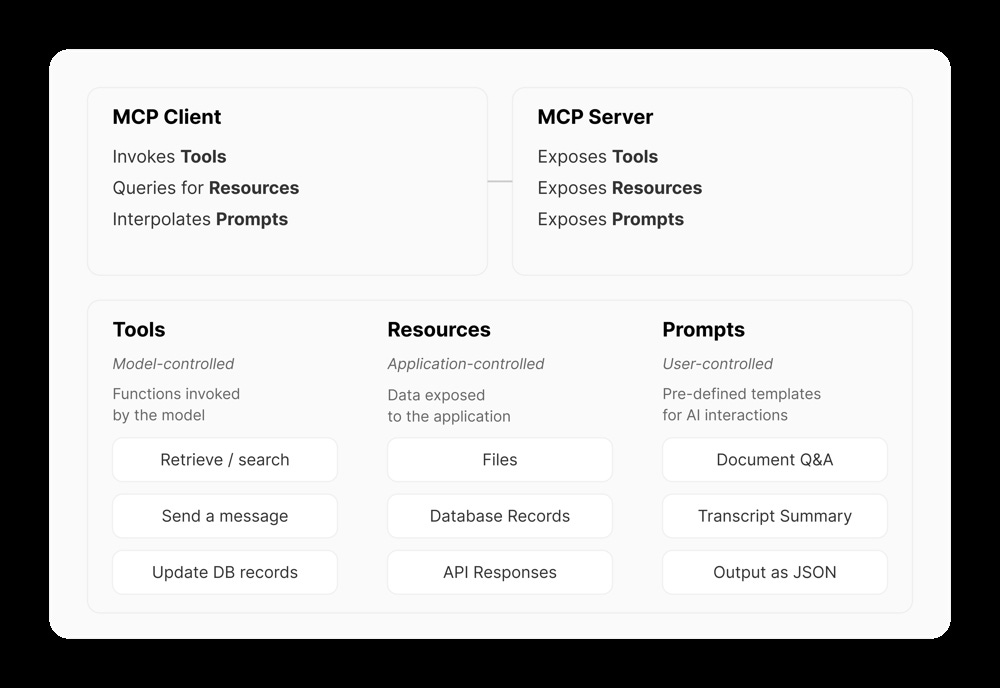
Tools – Model-controlled functions: Tools represent actions or functions that the AI model can decide to call during its reasoning process . For example, a tool could be “send an email,” “fetch current weather,” or “execute a database query.” Each tool is defined by a name, a human-readable description, and an input schema describing what arguments it accepts . The input schema is given in JSON Schema format (defining expected parameters and types), so that the client (or the LLM via function-call interfaces) knows how to call the tool . Tools are invoked actively by the AI (often via function calling in the LLM) when it determines some step requires that action. Because tools can have side effects or perform significant computation, they usually require user approval or are run in a controlled sandbox. In MCP, the client can list available tools (tools/list) and call a chosen tool (tools/call) by name .
Resources – Application-controlled data: Resources are pieces of data or content that the server makes available for the AI to read . They can be thought of as read-only endpoints or documents – for example, the contents of files, database records, API responses, or even images and logs . Each resource is identified by a URI (a structured path like a URL or file path) which the server uses to locate the data . Clients typically fetch resource listings or specific resource content on behalf of the user. Unlike tools, resources do not perform actions; they simply provide information (no side effects) . An MCP server might expose, say, a list of recent files or records as resources. The client (or user) then decides which resources to actually pull into the conversation. In practice, clients call resources/list to discover what resources (URIs and metadata) are available, and then call resources/read (or resources/get) to retrieve the content of a resource by its URI . The server returns the content (text or binary data, possibly broken into chunks if large) along with a MIME type or format indicator . Resources are typically curated or selected by the application or user; for example, a user might click to attach a document into the AI’s context, triggering the client to fetch that resource via MCP.
Prompts – User-controlled templates: Prompts in MCP are predefined prompt templates or workflow scripts that the server can supply to help structure interactions . Essentially, these are canned pieces of conversation (or prompt engineering recipes) that can be inserted or run to achieve specific tasks. For example, a server might offer a prompt called "Document Q&A" that, when requested, returns a series of message templates instructing the LLM how to analyze a document. Each prompt is defined by a name, an optional description, and possibly a set of arguments/parameters it accepts (for instance, a prompt might take a filename or a timeframe as input) . MCP clients can list available prompts (prompts/list) and then request a specific prompt by name (prompts/get), providing any required arguments . The MCP server then generates the full prompt content, often as an array of chat messages or instructions, which the client can inject into the LLM’s context . Because prompts are intended to be explicitly chosen by users or developers (not arbitrarily by the AI), they are considered user-controlled. Prompts are a powerful way to encapsulate best-practice workflows (for example, a multi-step chain of reasoning or a particular style of query) that can be shared between applications via MCP.
In addition to these three main categories, MCP defines other supporting concepts. One important concept is “roots”, which are suggested root URIs or context boundaries that a client can send to a server when connecting. For example, a client might tell a filesystem server that the root of interest is file:///home/user/project, so the server should focus on that directory . Roots help scope the server’s operations (though they are not a security mechanism by themselves) and provide clarity about what portion of data the AI is working with . Another concept is “sampling” and rate limits, ensuring the server doesn’t overload the client with data and that large contexts can be sampled or chunked – but these are advanced details beyond a high-level overview.
Data format and communication: MCP messages are encoded in JSON and follow JSON-RPC 2.0 conventions. For example, when an AI client wants to list available tools from a server, it sends a request like:
{ "jsonrpc": "2.0", "id": 1, "method": "tools/list" }The server would respond with a list of tools and their schemas in a JSON response:
{ "jsonrpc": "2.0", "id": 1, "result": {
"tools": [
{ "name": "calculate_sum", "description": "Add two numbers",
"inputSchema": { "type": "object", "properties": { "a": {"type":"number"}, "b": {"type":"number"} } }
},
...
]
} }All MCP methods (like tools/list, tools/call, resources/list, resources/read, prompts/list, prompts/get, etc.) follow this request/response pattern. For one-way notifications (where the server might proactively send an update), JSON-RPC notifications (with no id) are used. The protocol ensures that each request id is matched with a corresponding result, so the client can handle multiple outstanding requests concurrently if needed. Thanks to JSON-RPC, error handling is also standardized (with error codes and messages in a structured error field on responses if something goes wrong) .
Overall, the MCP architecture cleanly separates the what (capabilities like tools/resources/prompts) from the how (the transport and JSON messaging). This allows developers to focus on implementing the functionality of a server without worrying about compatibility with each AI system – if both sides adhere to MCP, they can work together.
How MCP Works in Practice (Workflow)
In a practical AI system pipeline, MCP enables a dynamic, on-demand exchange between the AI and external data. Here is an end-to-end example of how an AI assistant might utilize MCP, broken into steps:
Initialization & Handshake: When the host application (AI assistant) starts, it launches or connects to the MCP server(s) it will use. During this initial connection, a handshake occurs where the client and server exchange information about themselves – e.g. the server may send its name and version, and the client may confirm the MCP protocol version or send initial settings . At this stage, if the client has any root URIs or scope hints (e.g. a directory path for a filesystem server), it provides them to the server . The handshake ensures both sides understand each other’s capabilities and agree on the protocol features to use.
Discovery of Capabilities: After connecting, the client queries the server for its available capabilities. The client will typically call the list methods for each type of capability the server supports. For example, if the server indicated it has Tools and Resources, the client sends a
tools/listrequest and aresources/listrequest. The server responds with metadata: a list of tools (names, descriptions, input schemas) and a list of resources (URIs, names, types) . Similarly,prompts/listwould return any predefined prompt templates. This discovery phase is crucial – it tells the AI (and potentially the user) "Here’s what this server can do or provide." The host application might use this information to present options to the user (e.g. showing a list of files from a filesystem server), or to prepare the LLM by informing it about available tool functions.Context Provisioning: At this point, the host application integrates the discovered context into the AI’s environment. For resources, which are application-controlled, the client or user might select certain resources to actually fetch. For instance, the user could pick a specific file from the list, and the client would then call
resources/readto retrieve its content and insert that content into the LLM’s context window (as additional text) . For tools, which are model-controlled, the client translates the tool definitions into a format the model can understand – often this means providing the tool list to the LLM via a system message or using the model’s function-calling format (if the LLM supports function calls) . Prompts, being user-controlled, might be shown as preset options (for example, a dropdown of possible workflows) for the user to choose, after which the client would fetch the selected prompt (prompts/get) and supply it to the model before generating a response. This step is about making the external context accessible to the AI: either by pre-loading data (resources/prompts) or by informing the AI about callable tools.Invocation (AI makes a request): Now the AI model begins processing the user’s query with the additional context at hand. If, during its reasoning, the model decides it needs more information or needs to take an action, it will trigger the use of an MCP capability. In a tools-enabled scenario, this often manifests as the model choosing to invoke a tool. For example, if the user asked, “What are the open issues in project X?”, the LLM might determine it should call a tool like
get_open_issuesfrom a GitHub MCP server. The host (MCP client) detects the model’s intent (via a function call output or other protocol) and sends atools/callrequest to the appropriate MCP server with the chosen tool name and arguments . In a resources scenario, the model might ask for a specific piece of data, and the client would issue aresources/readif not already done. Essentially, at this step the AI (via the client) invokes the MCP server’s help through a request.Execution by MCP Server: Upon receiving the invocation request, the MCP server performs the required operation. For a tool call, this means running the function associated with that tool – e.g. making an API call, querying a database, running a computation – whatever logic the server developer implemented for that tool . For a resource request, this means reading the data (from disk, memory, or an API) and possibly converting it to the expected format. This execution happens inside the server’s controlled environment, isolated from the AI model (for safety). For example, if the tool is to fetch weather data, the server will call the Weather API and gather the result. Notably, the MCP server can enforce access control or transformations here (ensuring, for instance, that only allowed files are read, or redacting sensitive info). Execution may be quick (a database lookup) or lengthy (a web search); the protocol supports asynchronous handling, and if using SSE, streaming partial results is possible. In all cases, the server eventually prepares a response message containing the results or an error if something went wrong.
Response and Integration: The MCP server sends the results back to the client as a JSON-RPC response. For our example, the GitHub issues tool might return a JSON payload with the list of open issues (titles, URLs, etc.) or a summary. The client receives this and hands it to the host application. The host then integrates the result into the AI’s context. If the AI model supports function call responses natively (as with OpenAI function calling or similar), the result might be fed back for the model to consume in the next turn. Alternatively, the client might inject the result into the conversation as a system or user message (e.g. “Here are the open issues: ...”). At this point, the LLM has fresh external information that it didn’t originally know, and it can continue answering the user’s query with that new data . The final answer is generated by the model, using both its internal knowledge and any retrieved context.
Iteration or Completion: The cycle may iterate if the model needs to call additional tools or fetch more data. Otherwise, the AI produces a final answer for the user. From the user’s perspective, this all feels like a single coherent interaction – they asked a question and got a richer answer that took into account, say, their private documents or live data. Under the hood, MCP enabled the secure retrieval of that data. The user might not even realize a second system (the MCP server) was involved, aside from perhaps granting permission for the AI to use a tool. The host application might log the tool usage or resource used for transparency. Once the conversation is done, the client can gracefully close the connection to the MCP server or keep it open for future queries.
Throughout this workflow, security and control are paramount. The MCP design keeps the potentially powerful or sensitive operations in the server (which is under the developer’s control), rather than in the LLM itself. The AI model cannot arbitrarily access a tool or data source unless the MCP server explicitly exposes it and the client allows it. This two-layer structure (AI model ↔ MCP client ↔ MCP server ↔ actual service) provides natural checkpoints for authorization. For example, an MCP server connected to an email account might require an OAuth token and could be coded to refuse sending emails outside a certain domain. The user/administrator thus has fine-grained control over what the AI can do. MCP’s standardized nature also makes auditing easier – since all tool calls go through a common protocol, logging and monitoring can be uniform across different integrations.
In summary, MCP enables an agentic loop where the AI can iteratively pull in external information or execute tasks, all mediated by well-defined interfaces. This greatly expands the utility of AI assistants (they are no longer limited to their training data), while keeping integrations modular, secure, and reusable across different AI systems .
Building an MCP Server from Scratch
Building an MCP server involves implementing the protocol’s requirements and wiring them to your chosen data source or functionality. At a high level, creating an MCP server from scratch entails the following core steps and components:
1. Determine the capabilities to expose: First, decide what your server will provide – is it exposing tools (operations the AI can invoke), resources (data the AI can read), prompts, or some combination? This depends on the use case. For instance, a server for a weather service might expose a tool (get_weather) and perhaps a prompt template for formatting weather reports, whereas a server for a file system might primarily expose resources (files) and a few tools (like search_files). Clearly defining the scope will guide the implementation.
2. Implement the MCP interface (schema): MCP servers must respond to certain standardized requests (per the MCP spec). Concretely, you will need to implement handlers for methods such as:
tools/list– return the list of available tools with their names, descriptions, and input schemas.tools/call– execute a specified tool with given arguments and return the result.resources/list– return a listing of available resources (each with a URI, name, and maybe type/metadata).resources/read(orget) – retrieve the content of a specified resource URI (text or binary data, possibly chunked).prompts/list– list available prompt templates (names, descriptions, argument schema).prompts/get– given a prompt name (and args), return the full prompt content (usually a series of messages or instructions).Additionally, handle any protocol-level messages (like handshake or ping, which the SDK often takes care of).
If you use an MCP SDK (which is highly recommended), much of the low-level protocol handling is done for you. For example, Anthropic’s TypeScript and Python SDKs provide classes where you can simply register your tools/resources, and the SDK will automatically implement the list and call methods, JSON-RPC encoding, etc. . If coding without an SDK, you’d need to follow the MCP specification documentation to ensure your server speaks JSON-RPC correctly and adheres to the expected request/response schemas for each method.
3. Develop the logic for each capability: This is the core functionality of your server – essentially writing the “business logic” behind each tool or resource.
For each Tool: implement the action it performs. For instance, if you’re building a GitHub integration, a tool might be
create_issue– you’d write the function to call GitHub’s API to create an issue. Make sure to validate inputs against the tool’s schema, handle errors (like network failures), and format the output as MCP expects (typically as acontentfield containing text or data) . The output can be plain text or structured JSON (often returned as a text blob); it’s whatever you want the AI to receive.For each Resource: implement how to fetch that data. You might need to connect to a database, read a file from disk, or call an API. When listing resources, decide how to paginate or filter if there are many. In the read handler, retrieve the content and return it along with a
mimeTypeand the sameuriso the client/AI knows what it is . If the data is large, you might break it into multiple pieces or use streaming (MCP can handle streaming via SSE or sending partial content in sequence).For Prompts: define the static template or dynamic generation process. The prompt content will likely be a series of messages (with roles like
userorsystem) and placeholders filled in from arguments . The server should output them in the format the client expects (the MCP spec outlines a standard format for messages with roles and content types – text or resource references, etc.).
4. Establish the server’s metadata: Each MCP server has identifying info and versioning. In code, you typically instantiate a server with a name and version string . The name might be something like "mcp-github" or "companyX-drive" – it should uniquely identify the integration. Versioning helps in case the protocol or capabilities change over time. Also, when initializing, you declare what capabilities you support (tools/resources/prompts/roots) so the client knows what to expect . The SDKs usually require you to specify this (often by providing a capabilities object, e.g. { tools: {}, resources: {} } to indicate you have those features) .
5. Choose a transport and run the server: Decide how your server will receive requests from clients. For local scenarios, running the server as a separate process and using stdio transport is straightforward – your server will read JSON requests from stdin and write responses to stdout . This can be done by simply launching the server program when needed (e.g., Claude Desktop might spawn the process for a local MCP server). For network scenarios or multi-user servers, you might implement an HTTP endpoint with SSE as demonstrated in the SDK (the server holds open an SSE stream for sending events and accepts POST requests for incoming messages) . In either case, the server code needs to call a loop or method to start listening for requests. With SDKs, this might be as easy as server.connect(transport) where transport is an instance of Stdio or SSE transport class . From scratch, you’d set up a simple event loop: read JSON from a socket or stdin, parse it, handle accordingly, and output the JSON response. Ensure your server can run continuously and handle multiple requests sequentially or in parallel as needed.
6. Test and iterate: Once implemented, it’s important to test your MCP server with an actual client or a debugging tool. The MCP community provides an “MCP Inspector” tool for testing servers by sending manual requests . You can also write a small MCP client or use existing ones (for example, a CLI client or even an LLM that supports function calling with MCP as a backend). Check that listing calls return the correct schema, that tool calls produce the expected results, and that error conditions (like invalid params) return proper JSON-RPC errors. Because the protocol is open, you can use common tools (even curl for HTTP transports or simple scripting for stdio) to simulate requests.
7. Security and performance considerations: When building from scratch, pay attention to security. Only expose what’s necessary and sanitize any inputs/outputs. If your server connects to internal databases or systems, ensure it has appropriate access controls. Remember that an AI might be coaxed by a clever user into requesting something sensitive – your server should be the gatekeeper that prevents unauthorized access. Consider adding checks: e.g., if a requested file path is outside an allowed directory, refuse the request. Also consider performance: large data should be chunked or summarized (the MCP spec allows for streaming via sending partial responses). Use caching if the data is expensive to fetch repeatedly, but also provide fresh data when needed.
To illustrate, imagine building a simple MCP server for a to-do list application. You decide to expose a tool called add_task (for the AI to add a new to-do item) and a resource listing of all tasks. You would write handlers so that:
tools/listreturns something like[ {name: "add_task", description: "Add a new to-do item", inputSchema: {...}} ].tools/callforadd_tasktakes the task description as input and, say, inserts it into a local file or database, then returns a confirmation message.resources/list returns a list of tasks with URIs like
task://1for task ID 1, each with maybe the title as the name.resources/readfor atask://idfetches that task’s details and returns the text content (e.g. "Buy milk – not done"). When the AI runs, it could calladd_taskvia MCP instead of just telling the user "I have added it" – thereby actually performing the addition in the external system. Or it could retrieve the list of tasks to answer a question like "What’s on my to-do list?".
In practice, you rarely need to start completely from scratch. The MCP team provides SDKs and reference implementations to jump-start development . For example, the official MCP servers repository includes ready-made servers for things like Google Drive, Slack, GitHub, etc., which demonstrate how to implement various patterns . You can often begin by copying an example server and modifying it for your needs. The SDKs also handle subtleties like protocol versioning, so you can focus on your integration’s logic.
To get a basic MCP server up quickly, one interesting approach is to use AI assistance itself – Anthropic noted that their model Claude 3.5 was capable of helping write MCP server code from descriptions . While you should verify any AI-generated code for correctness and security, this hints that building MCP servers can be quite streamlined (sometimes just a few dozen lines of code for simple cases).
Examples of MCP Use Cases and Tools
Because MCP is a general protocol, it can be applied to many scenarios. Here are a few notable use cases and existing open-source MCP servers:
Document Retrieval and Q&A: An MCP server can expose a company’s document repository or knowledge base as resources. For example, a Google Drive MCP server can list and fetch files from a drive . An AI assistant (client) can use it to retrieve relevant PDFs or docs when a user asks a question that might be answered in those files. This is effectively a Retrieval-Augmented Generation (RAG) setup: the MCP server handles finding and returning the text, and the LLM uses it to craft a more informed answer.
Coding Assistants and IDE Integration: Developer tools are leveraging MCP to give AI coding assistants access to project context. Consider an IDE like VS Code or Replit: an MCP server could provide access to the user’s git repository. Indeed, there are MCP servers for Git and GitHub that let an AI list repository files, read file contents, search code, or open issues . Sourcegraph’s Cody uses an MCP server to integrate with issue trackers (like Linear) so that it can bring in ticket details during a coding session . Similarly, Codeium and Zed are exploring MCP to allow AI to navigate and modify code bases. This means a code assistant can answer questions like “What does function X do?” by actually opening the file via MCP and reading it, rather than relying solely on pretrained knowledge.
Messaging and Productivity Tools: MCP servers exist for Slack, email, and calendars. A Slack MCP server could allow an AI to fetch recent messages from a channel (as resources) or even send a message via a tool call. This opens up use cases like an AI office assistant that can read updates from Slack or post reminders on your behalf (with your permission) . Similarly, an email MCP server might let the AI draft an email (the tool returns the draft text) or schedule meetings via a calendar API. Because MCP is two-way, the AI could both retrieve info (upcoming events) and take actions (create a calendar entry) through the same server.
Web Browsing and Search: There are MCP servers designed to fetch web content. For instance, the Brave Search server uses Brave’s Search API to allow an AI to perform web searches . A Fetch server can take a URL and return the page content (with boilerplate removed) for the AI to read . These are analogous to browser plugins but standardized. An AI agent using these could answer current-events questions or cite information from the live web. Another example is a Puppeteer MCP server that the AI can instruct to open a headless browser and even click or fill forms, then return a screenshot or page text . This hints at automating web tasks via MCP tools.
Databases and Analytics: MCP servers can interface with databases or analytics backends. A PostgreSQL read-only MCP server exists, which allows an AI to run SQL queries (through a tool) and retrieve results . This could be used by a data analyst assistant AI: the user asks a question, the AI forms a SQL query and uses the MCP tool to execute it, then gets the results and explains them. Similarly, there are integrations for analytics APIs (one example from the community is an MCP server for the Plausible analytics service, which lets the AI fetch website stats via a tool) .
Local System Access: Some MCP servers aim to give AI assistants controlled access to local machine resources. For example, a Filesystem MCP server can list directory contents and read files from the user’s computer (subject to configured access controls) . This could let an AI assistant open a local document the user references in a conversation. Another interesting one is a Memory server that provides a persistent storage (like a knowledge graph or vector store) so the AI can “remember” information between sessions . In all these cases, MCP provides a sandboxed way to expose parts of the local environment to the AI, without just giving the AI free rein.
Agentic Workflows: By combining tools and prompts, one can set up complex workflows. For instance, an MCP server might have a prompt called "TranslateDocument" which, given a file URI, will return a sequence of messages that instruct the AI to use a translation API tool on each part of the text (this is hypothetical, but illustrates how prompts and tools together can orchestrate multi-step processes). Companies like Block have spoken about using MCP to build “agentic systems” that offload mechanical tasks from humans . Because MCP can be extended, one can imagine custom prompts and tools for internal processes (like an AI agent that checks your code into git, then triggers a CI pipeline, etc., all via different MCP servers coordinating).
Many of these use cases are already supported by open-source MCP servers released by Anthropic and the community. The official MCP GitHub repository lists integrations for Google Drive, Slack, GitHub, GitLab, Notion, Jira, Confluence, databases, and more . If you need a certain integration, there’s a good chance someone has started an MCP server for it. The benefit of using MCP is that an AI application (client) that knows how to talk to one server can talk to any of them; switching from one data source to another is just a matter of pointing the client to a different server URL or process.
Code Example: Basic MCP Server and Usage
To solidify understanding, let’s look at a simplified code example of an MCP server and how an AI client would interact with it. We’ll use Python for the server example, leveraging the FastMCP library (a high-level wrapper in the official Python SDK that simplifies MCP server creation) . This server will expose one tool and one resource for demonstration:
from fastmcp import FastMCP
# Initialize an MCP server instance with a name
mcp = FastMCP("DemoServer")
# Define a simple tool that adds two numbers
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
# Define a resource that provides a greeting message for a given name
@mcp.resource("greeting://{name}")
def get_greeting(name: str) -> str:
"""Get a personalized greeting"""
return f"Hello, {name}!"In the code above, we created an MCP server named “DemoServer” and added:
A tool called
add– it takes two integers and returns their sum. The@mcp.tool()decorator automatically registers this function as a callable tool and infers its input schema (two required integers) from the type hints . The docstring “Add two numbers” would be used as the tool’s description.A resource pattern
greeting://{name}– this means the server will treat any URI with schemegreeting://as a resource. The{name}in the URI is a variable. We implementget_greeting(name)to handle such resources, simply returning a friendly greeting string. So if the client later requests the resourcegreeting://Alice, the server will callget_greeting("Alice")and return"Hello, Alice!"as text content.
After defining tools and resources, we would normally start the server. With FastMCP, one can simply run (for stdio transport):
fastmcp run myserver.pywhich launches an event loop waiting for JSON-RPC requests. (In pure SDK usage, you’d call something like mcp.run_stdio() to listen on stdin/stdout.)
Client Usage Scenario: Now, how would an AI or client actually use this server? Let’s say an AI assistant wants to use the above server to greet a user. The sequence might look like:
1. Listing capabilities: The client might first ask the server what it has. This corresponds to tools/list and resources/list. For example, the client sends:
{"jsonrpc":"2.0", "id":1, "method":"tools/list"}2. The server would reply with a list including the add tool (and its schema). Similarly, {"method":"resources/list"} might not list every possible greeting (since {name} is a pattern), but the server could optionally list a template or nothing (this is a trivial example). In many cases, resources/list could enumerate known items; in this case, greetings might be generated on the fly so it might not enumerate.
3. Using the tool (invocation): Suppose the user asks the AI, "What's 3 + 4?" The AI decides to use the add tool (instead of calculating itself – contrived, but for example’s sake). The MCP client would send a request to call the tool:
{
"jsonrpc": "2.0",
"id": 2,
"method": "tools/call",
"params": { "name": "add", "arguments": { "a": 3, "b": 4 } }
}4. The MCP server’s add function executes and returns:
{
"jsonrpc": "2.0",
"id": 2,
"result": {
"content": [ { "type": "text", "text": "7" } ]
}
}5. Here, the result is wrapped in a content list (this is how MCP formats tool outputs; a tool can return multiple pieces of content, e.g. if an operation had multiple outputs). The client takes the "7" and gives it to the LLM, which can then respond to the user: “3 + 4 = 7”.
6. Using the resource: If the user asked, "Can you greet Alice for me?" the AI might choose to fetch the greeting resource. The client would send:
{"jsonrpc":"2.0", "id":3, "method":"resources/read",
"params": { "uri": "greeting://Alice" } }7. The MCP server recognizes the URI matches the greeting://{name} pattern, calls get_greeting("Alice"), and returns:
{
"jsonrpc": "2.0",
"id": 3,
"result": {
"contents": [ {
"uri": "greeting://Alice",
"mimeType": "text/plain",
"text": "Hello, Alice!"
} ]
}
}8. The client receives the greeting text. It might directly insert that into the chat with the user, or let the LLM know that the resource “greeting://Alice” equals "Hello, Alice!". The AI can then respond in conversational format, e.g., "Hello, Alice!".
In both cases, the interaction with the MCP server is happening behind the scenes in milliseconds, orchestrated by the client. The user experience is that the AI assistant suddenly knew the answer to something it didn’t before (like accessing an external calculator or a stored greeting).
This basic example hardly scratches the surface – real MCP servers might involve authenticating to external APIs, error handling (e.g., what if add received a string instead of number? The server would return a JSON-RPC error), and streaming large responses. But it showcases the essence of MCP: an AI model extending its abilities by querying a purpose-built external program in a standardized way.
To further explore, you can find many code examples and tutorials in the wild:
The official Anthropic MCP repository on GitHub contains reference servers in TypeScript and Python (for Slack, Google Drive, GitHub, etc.) which serve as great concrete examples .
Community blogs provide step-by-step guides, for instance, creating an MCP server for a web analytics API (Plausible) with detailed code walkthrough , or integrating MCP servers with frameworks like LangChain and Quarkus .
The MCP specification is available online, and the SDK documentation includes Quickstart examples in multiple languages. If you’re building your own, these resources help ensure you follow the expected data formats.
MCP is still evolving (as of 2025), but it has a robust foundation and growing adoption. By understanding the concepts and using the provided tools, developers can empower AI systems with real-world context and actions in a consistent, secure manner. The Model Context Protocol effectively bridges the gap between isolated AI models and the rich ecosystems of data and services they need to interact with, making advanced AI integrations far more accessible to build and maintain.
Other Interesting Reads on Model Context Protocol:
Anthropic, “Introducing the Model Context Protocol,” Nov 2024
Philschmid, “Model Context Protocol (MCP) – an overview,” Apr 2025
Model Context Protocol – Official Documentation and Specification, 2024
Sourcegraph Blog, “Cody supports additional context through Anthropic’s MCP,” 2024
Michael Wapp, “Creating a Model Context Protocol Server: A Step-by-Step Guide,” Medium, Mar 2025
GitHub – modelcontextprotocol/servers (Anthropic’s reference MCP servers repository)
Anthropic Documentation – MCP Concepts (Tools, Resources, Prompts, Transports, Roots)
Anthropic API Reference – Model Context Protocol (MCP)